Introduction
The number of older adults with cancer is rapidly growing.1 In North Carolina, approximately half of the 60,000 incident cancers diagnosed annually are in adults aged over 65 years.2 Approximately 20,000 North Carolinians die of cancer each year, making it the second leading cause of death in the state.2
Non-experimental “big data” has been proposed as a way to generate evidence related to health and health care delivery and is a valuable tool for geriatric oncology research.3,4 Big data includes large databases collected outside of highly controlled clinical trial settings. In this commentary, we provide an overview of the types of big data that can be used for geriatric oncology research to complement data generated in clinical trials.
Types of Big Data
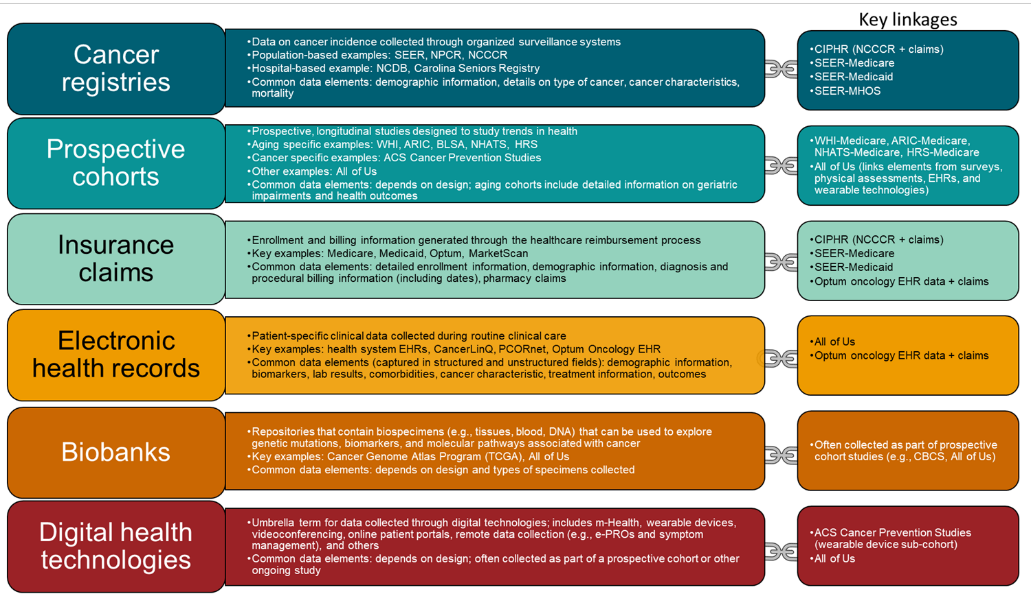
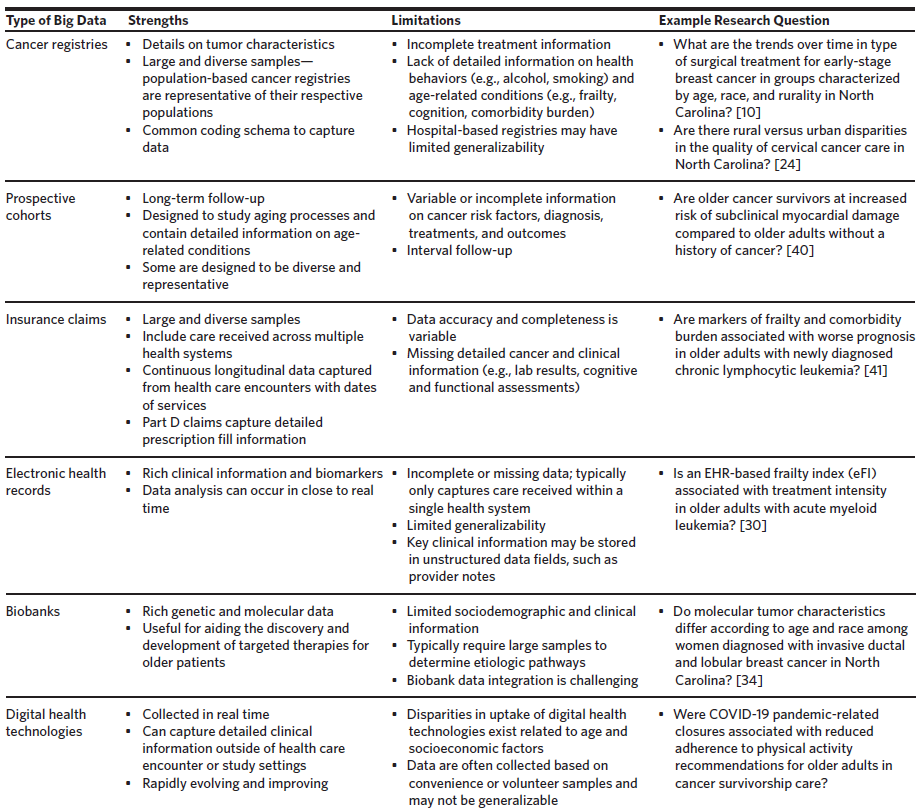
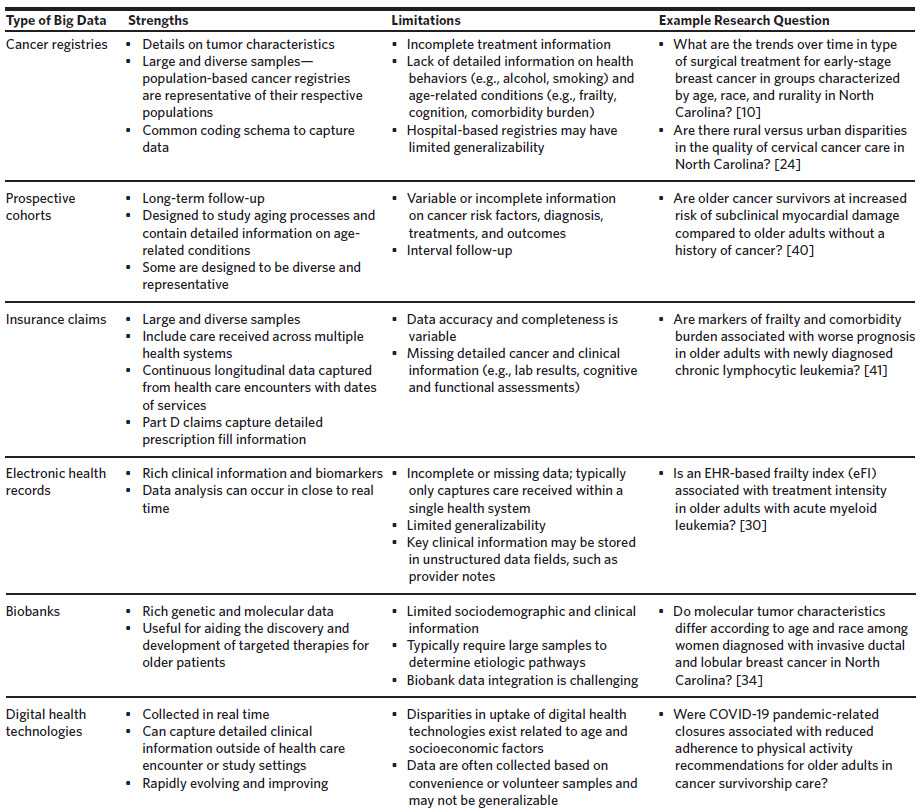
A summary of types of big data available for geriatric oncology research, their strengths and limitations, and example research questions are provided in Figure 1 and Table 1. Additional databases and details are provided on the Cancer and Aging Research Group website: www.mycarg.org.

Cancer Registries
Cancer registries are surveillance systems that collect data on incident cancers within health systems, populations, or regions. The two largest population-based cancer registries are the Surveillance, Epidemiology, and End Results (SEER) program and the National Program of Cancer Registries (NPCR). SEER is a collection of cancer registries that covers a diverse sample with respect to geography, race, ethnicity, and socioeconomic status. SEER has been linked to other data sources, including the Medicare Health Outcomes Survey (MHOS), which collects information on patient-reported outcomes, function, and quality of life, as well as insurance claims data. NPCR is the CDC’s cancer surveillance system that provides population-based information on cancer incidence on the national and state levels. The North Carolina Central Cancer Registry (NCCCR) is a participant in the NPCR and includes complete cancer incidence data for North Carolina. Given the diversity of these cancer registries, SEER and NPCR data are frequently used to conduct health disparities research.5
In addition to population-based cancer registries, several hospital-based cancer registries exist in the United States. The largest is the National Cancer Database, which collects information for patients receiving care within hospitals that have Commission on Cancer accreditation, covering approximately 70% of incident cancers in the United States.6 In North Carolina, the Carolina Seniors Registry (CSR) is a registry of older adults with cancer receiving care in academic or community oncology clinics. The CSR captures geriatric assessment data for all participants, making it a valuable source for understanding geriatric impairments in older adults with cancer.7
Cancer registries are valuable for understanding trends in cancer incidence and mortality in older adults. However, they typically only capture limited information on treatment, outcomes other than survival, and age-related conditions (e.g., frailty, cognition, comorbidity). Findings from hospital-based cancer registries may not be generalizable to the full US population.
Prospective Cohorts
Several longitudinal prospective cohorts have been established to study trends in aging. In the United States, examples include 1) the Women’s Health Initiative,8 2) the Atherosclerosis Risk in Communities Study,9 3) the Baltimore Longitudinal Study of Aging,10 4) the National Health and Aging Trends Study,11 5) the Health and Retirement Study,12 and 6) the Health, Aging and Body Composition Study.13 Although not exclusively established for cancer research, these studies contain large samples of older cancer survivors. Their key strengths include long-term follow-up and detailed information on age-related conditions and health determinants. However, the granularity of information pertaining to cancer risk factors, diagnoses, treatments, and outcomes is variable. The American Cancer Society’s Cancer Prevention Studies are a series of prospective cohorts that follow adults without cancer to identify risk factors for incident cancer.
A novel longitudinal cohort for health research is the All of Us Research Program, which will enroll 1 million adults.14 All of Us links data from surveys, electronic health records (EHRs), physical assessments, biospecimens, and digital health technologies. Many of these data elements are described in additional detail in this paper.
Insurance Claims
Insurance claims data contain detailed enrollment and billing information generated through the health care reimbursement process. Data elements include demographics, dates of enrollment, and diagnosis and procedural information from health care encounters. Medicare claims and enrollment data are particularly well-suited for research in older adult populations as they include most older adults in the United States. Claims capture continuous health care encounter information across health systems and are well-suited for pharmacoepidemiologic research, as they capture detailed prescription fill information for older adults covered by Medicare Part D.
The largest challenge with claims data is that information is collected for reimbursement and does not capture granular clinical details, including measures of function and cognition. Researchers have developed claims-based comorbidity and frailty indices to identify geriatric impairments for studies using Medicare claims data, which have been used extensively for geriatric oncology research.15,16
An increasing number of data linkages with Medicare and other claims databases that are useful for geriatric oncology research are becoming available. SEER-Medicare links cancer registry data with claims data for older adults living in SEER regions covered by fee-for-service or Medicare Advantage plans.17 The Cancer Information & Population Health Resource (CIPHR) housed at the UNC Lineberger Comprehensive Cancer Center includes person-level linkage between the NCCCR and administrative claims for North Carolinians covered by Medicare, Medicaid, and private insurers.18 CIPHR represents a diverse sample with respect to age, geography, race, and ethnicity, making it well-suited for cancer health disparities research.19 Medicare claims have also been linked to prospective longitudinal cohorts including the Women’s Health Initiative, the Atherosclerosis Risk in Communities Study, the National Health and Aging Trends Study, and the Health and Retirement Study.
Electronic Health Records
EHRs include patient-specific information collected during routine clinical care. Data are captured in both structured and unstructured (e.g., provider notes) fields and can be used to answer a wide range of research questions related to the health and well-being of older cancer survivors.20 North Carolina is home to three NCI-designated comprehensive cancer centers (Wake Forest Baptist Comprehensive Cancer Center, UNC Lineberger Comprehensive Cancer Center, Duke Cancer Institute) and four Department of Veterans Affairs (VA) Medical Centers, which have robust EHR data systems that can be leveraged for geriatric oncology research. National EHR data resources, such as PCORnet, CancerLinQ, and the Optum Oncology EHR Data, are also available for research.21–23
Studies using EHR data may have limited generalizability as they are typically limited to a single health system. Another challenge of EHRs is missing or incomplete information. Clinical information may be stored in unstructured data fields that are challenging to analyze (e.g., comorbidities or frailty).24 Researchers have attempted to fill these gaps through advancement of natural language processing and machine learning methods. For example, researchers at Wake Forest Atrium Health Baptist have developed an EHR-based frailty index (eFI) that is implemented within the EHR. The eFI has been shown to be strongly associated with important treatment outcomes, such as chemotherapy intensity (anthracycline versus non-anthracycline-based regimen).25 Additional research is needed into how the eFI can be used in the cancer pathway to improve outcomes in older adults with cancer.
Biobank Data
Biobank repositories contain biospecimens such as tissue samples, blood, and DNA that can be used to explore genetic mutations, biomarkers, and molecular pathways associated with cancer. As the complexity of treating older adults with cancer continues to grow, biobanks have the potential to enhance precision medicine efforts to consider aging and genetic factors when determining optimal treatments for older adult populations. One large cancer biobank in the United States is The Cancer Genome Atlas Program (TCGA), which has been used to understand cancer biology and develop novel diagnostic and therapeutic approaches.26 There is also an ongoing NCI effort to establish the Cancer Moonshot Biobank, a central repository of biospecimens that will be made available to cancer researchers.27
Biobanks are often collected as part of prospective observational studies. For example, the All of Us Research Program collects blood, urine, and saliva samples from participants.14 In North Carolina, the Carolina Breast Cancer Study (CBCS) was a population-based longitudinal study that collected tumor and blood specimens for breast cancer cases to identify genetic and social risk factors for breast cancer.28 The CBCS oversampled Black women and has been useful for assessing racial disparities in breast cancer risk factors.29
Biobanks typically require large samples to identify effects, which is a key challenge to their use. In addition, they are often based on convenience or volunteer samples and may have limited generalizability. Finally, biobank data integration is challenging, and additional efforts are needed to link biobanks to other data sources.
Digital Health Technologies
Digital health technologies include mobile health, wearable devices, online patient portals, and remote data collection technologies. These technologies are increasingly playing a role in cancer care delivery and research. For example, data collected from wearable technologies can be used to assess complications related to sleep, physical activity, mobility, posture, and falls in older cancer survivors.30 Prospectively collected data from wearable devices can help identify how physical activity and sedentary behaviors affect cancer risk and outcomes.31
One of the key challenges related to digital health technologies is disparity in uptake related to age and socioeconomic factors.32 In addition, data collected through digital technologies are often based on convenience or volunteer samples and may lack diversity and detailed clinical information. Efforts to link data captured using digital health technologies and other sources of health data can reduce these challenges and should be the focus for ongoing research efforts.
Discussion
In this commentary, we reviewed examples of non-experimental big data available for conducting geriatric oncology research, emphasizing resources available in North Carolina. While we could not cover all types of big data, we focused on resources that are particularly valuable for improving the geriatric oncology evidence base. We highlighted papers that used big data to identify and address health disparities. Big data typically includes diverse samples that better reflect older adults seen in routine oncology practice than highly controlled clinical trials. North Carolina, which has a diverse population with respect to age, race, ethnicity, geography, and socioeconomic status, is a useful setting for cancer disparities work.
Although big data is a promising solution for improving the geriatric oncology evidence base, it is subject to bias and requires careful consideration of study design and appropriateness for use. For example, insurance claims and EHR data are collected outside the realm of scientific inquiry and data on function and cognition are variable. Optimizing the measurement of important age-related conditions is critical for advancing this field. Data linkages are valuable tools for limiting biases that are common when analyzing non-experimental data. For example, while a limitation of Medicare claims data is a lack of granular cancer information, linkage with the SEER cancer registries allows researchers to harness the strengths of both resources. Future efforts are needed to create additional data linkages as digital health care capabilities continue to grow.
There are many research questions for which clinical trials are still necessary and there remains a critical need to build inclusive models for trials that adequately represent all older adults.33 These efforts have been the focus of several domestic and international partnerships and institutions, including the International Society of Geriatric Oncology’s Cancer and Aging Research Group, and the Rising Tide Foundation. In addition, novel hybrid design approaches that incorporate both trial data and big data can improve the generalizability of trial findings while reducing the concern for bias in non-experimental studies.34
Financial support
This work was supported by the Wake Forest Baptist Comprehensive Cancer Center (WFBCCC) Cancer Research Training and Education Coordination (CRTEC) program (National Cancer Institute grant P30CA012197). Dr. Bluethmann is supported by a Mentored Research Scholar Grant in Applied and Clinical Research, MSRG-18-136-01-CPPB, from the American Cancer Society (ACS).
Conflicts of interest
The authors report no conflicts of interest.